Interview: Hubble Integration Added to DigitalOcean Kubernetes
Exclusive Interview with DigitalOcean on Integrating Hubble into their Kubernetes Offering
Community
Exclusive Interview with DigitalOcean on Integrating Hubble into their Kubernetes Offering
Cilium 1.15 has arrived with Gateway API 1.0 Support, Cluster Mesh Scale Increase, Security Optimizations, and more
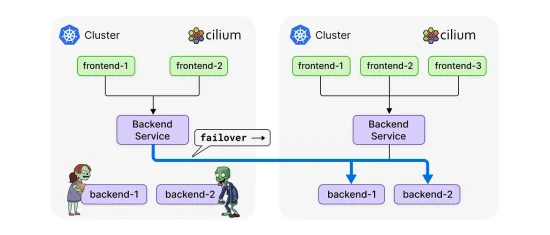
There is an amazing lineup of Cilium activities at KubeCon + CloudNativeCon
Cisco announced the completion of their acquisition of Isovalent, a contributor to the Cilium project
Learn how to use Cilium to provide networking services to containers inside Oracle Container Engine for Kubernetes
Learn how to configure Cilium Hubble with a local configuration file
Learn how to use Istio and Cilium in your EKS cluster
Les créateurs du fournisseur Cilium Terraform annoncent la sortie d'une nouvelle version et pourquoi le projet existe
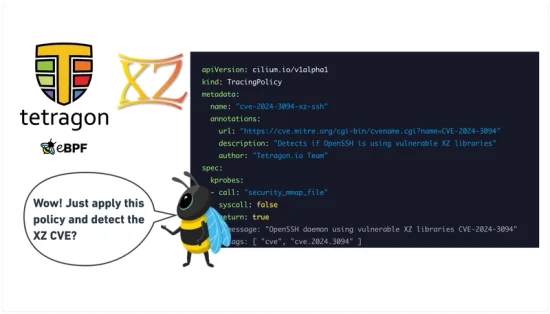
Learn how to use Tetragon to detect the XZ backdoor in OpenSSH
Learn how to install Cilium on Civo Cloud and how you can leverage Cillum network policies to secure cluster communication
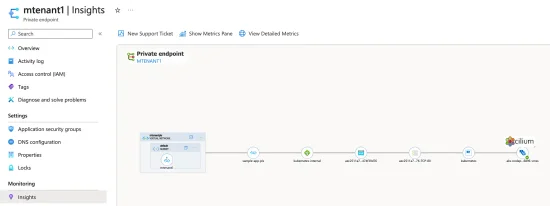
Learn how to access an AKS application externally via Private Link Service and restrict access to specific CIDR blocks with Cilium's Network Policy
InfoQ highlights KubeCon including updates on the Cilium and Tetragon projects
For live conversation and quick questions, join the Cilium Slack workspace. Don’t forget to say hi!
Join slack workspace